The practice of keeping sensitive keys in a .env file is a fundamental rule of modern development. It is the first line of defense that every developer learns. However, the rise of AI coding agents has introduced a subtle complication: keys are shared in agent chats and the agent might still end up creating a permanent record of those secrets elsewhere.

What We Found
Even when a developer is careful to use a .env file, the moment a key is mentioned in a chat or read by the agent to debug a connection, it is recorded. We found thousands of lines of session data tucked away in hidden folders. Within these logs, API keys and access tokens were sitting in plain text, completely unencrypted and accessible to anyone who knows where to look.

Good Memory Costs Something
You might wonder why these tools keep such detailed records. It comes down to a feature called conversation lookup. To provide helpful follow-up answers, Claude needs to remember what happened earlier in your session. By saving this history locally, the tool ensures that it does not lose its train of thought if you restart your terminal.
The problem is that these records are typically stored in files like history.jsonl inside the ~/.claude directory. Because AI agents transmit full conversation transcripts and tool outputs to their providers on every turn, any secret that enters the agent context becomes part of a long-lived on-disk artifact.
Verified Solution: Tool-Boundary Redaction
To fix this, we investigated using the internal hook system of the agent to create a transparent redaction layer. The goal is to allow the agent to use a secret locally while ensuring the real value never reaches the transcript or the API provider.
The real secret is resident only inside the PreToolUse process and the local subprocess; the model, the JSONL transcript, and the upstream API see only the placeholder.
The implementation works by teaching the model to use placeholders like @@SECRET:stripe_key@@. When the model tries to run a command, a series of invisible steps occur:
- A PreToolUse hook intercepts the command, looks up the real secret on your disk, and swaps the placeholder for the real value just before execution.
- To prevent the secret from leaking if the command prints it out, the hook wraps the entire command in a sed filter. This filter automatically scrubs the real secret out of the output and replaces it with the placeholder again before the model or the logs ever see it.
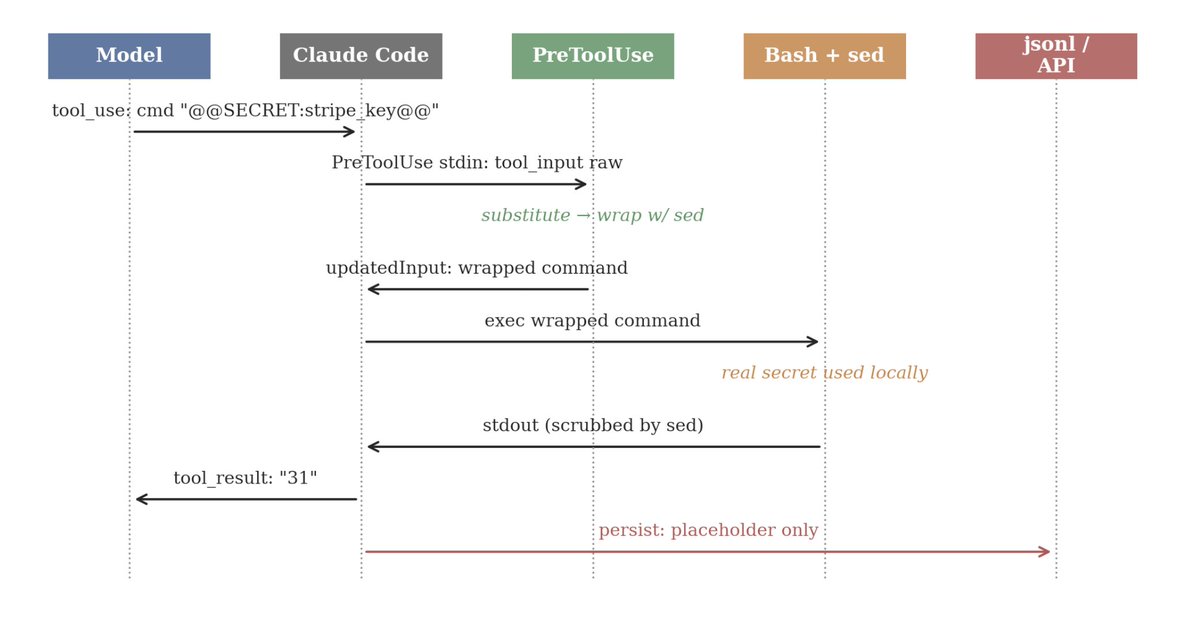
In testing, this “happy path” produced zero leaks across multiple bash calls, as the real value only existed temporarily in the local process.

How to Stop the Leaks
Even with these hooks, secrets can still slip through if an operator types them manually into a prompt or narrations. To build a complete defense, we developed a multi-layered approach:
- PreToolUse & PostToolUse hooks: Scripts to handle real-time tokenization and scrubbing.
- Post-hoc cleanup: Integrate a tool like Sweep, which acts as a post-hoc cleanup layer. It scans your agent caches for any residue that may have slipped through the hooks.
- Session-end sweeps: You can configure the agent to run a cleanup sweep automatically every time a session ends by using the PostStopSession hook.
- Operational Discipline: The most important step is to ensure that secret material is loaded into its designated directory outside of the agent session. If you never show the real secret to the model, the model can never accidentally repeat it.
By combining real-time prevention with regular cleanup, you can cover about 95% of the risk surface and keep your development environment safe from accidental exposure.
Open Source
Our research is free and open-source: github.com/PrismorSec/prismor